Unicode BiDi
TySE aims to handle international script well. This requires TySE to react to the challenges of bidrectional typsetting. The foundation of this is to implement the Unicode Standard’s Annex UAX#9, the Unicode Bidirectional Algorithm.
Unicode Bidirectional Algorithm
From the Unicode Annex document:
This annex describes specifications for the positioning of characters in text containing characters flowing from right to left, such as Arabic or Hebrew.
The Unicode Standard prescribes a memory representation order known as logical order. When text is presented in horizontal lines, most scripts display characters from left to right. However, there are several scripts (such as Arabic or Hebrew) where the natural ordering of horizontal text in display is from right to left. If all of the text has a uniform horizontal direction, then the ordering of the display text is unambiguous.
However, because these right-to-left scripts use digits that are written from left to right, the text is actually bidirectional: a mixture of right-to-left and left-to-right text. In addition to digits, embedded words from English and other scripts are also written from left to right, also producing bidirectional text. Without a clear specification, ambiguities can arise in determining the ordering of the displayed characters when the horizontal direction of the text is not uniform.
The Unicode Consortium describes a rather detailed algorithm to find this “positioning of characters.” There is even a blueprint implementation in C and Java. The downside is, however: This algorithm is … slightly complex, and consists in large parts of travelling back and forth within the text of a paragraph (while maintaining a stack). That makes the algorithm no easy read, and—more importantly—boring. I recognize the challenge of such an algorithm and I commend everone who takes it on them to code a literal implementation. For myself, however, I need a way to motivate me to wade into this. So let’s tackle the problem from a different perspective!
Complexity
Complexity of the algorithm derives, along others, from two properties:
- the handling of legacy scenarios
- handling of pathological nesting levels
My first step to reduce the problem domain is therefore straightfoward: drop both of these. My arguments are that TySE is a system for the future, so legacy problems should be rather an afterthought than the primary use case. And disregarding pathological nesting levels precludes TySE from being fully Unicode standard compliant, but for now I’ll take that risk. However, the reasoning behind both arguments is dubious, and just a pretext for having more fun while developing TySE.
The real source of complexity of the algorithm is of course, that the domain problem is hard. For border cases it is not easy to wrap your head around the possible ambiguities, more so, if you’re not routinely concerned with right-to-left script. I’d prefer having an appropriate data language to reason about the domain problem. How could this langauage, if there is on, look like?
A Text-Structuring Machine
One may view the bidi-algorithm as being divided into two phases:
- finding runs of characters wich share a common orientation (left-to-right or right-to-left)
- reordering the paragraph’s runs for display
UAX#9 explains it this way:
- Resolution of the embedding levels. A series of rules is applied to the lists of embedding levels and bidirectional character types. Each rule operates on the current values of those lists, and can modify those values. The original characters['] […] property values are referenced in the application of certain rules. The result of this phase is a modified list of embedding levels.
- Reordering. The text within each paragraph is reordered for display: first, the text in the paragraph is broken into lines, then the resolved embedding levels are used to reorder the text of each line for display.
For now we focus on the first phase, which is much more challenging than the second. The standard’s “modified list of embedding levels” is a fancy term for our character runs. In it’s essence, it is a hierarchy of structural brackets around runs of characters.
Example: The following snippet is from an W3C page about bidrectional text:
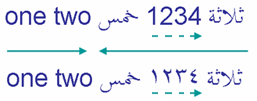

TySE uses the Twirp framework, with either GOB-encoded messages (to Go plugins) or JSON-encoded messages (to plugins written in other programming languages). Some ideas are taken from Pingo.

Configuration Tool
As configuring environments can be tedious, TySE provides an accompanying program to interactively setup environments. It
- writes and updates configuration files
- locates and downloads resources
- …
